

DCGAN – Deep Convolution Generative Adversarial Network, is a simpler variation of the GAN family. Used for solving many types of programs. However, one of the more known use cases is for generating images, especially faces of humans, cats and etc.
The basic idea behind GAN is to have two separate models. The first model is known as the generator. It will be responsible for generating images in the context of image generation. whereas the second model known as the discriminator will attempt to determine if an image is correct. In this case, it is very similar to a basic Convolution Network used for the classification of an image.
The generator uses an input, that is a value in the latent space, or more precisely, in this case, a vector in the latent vector space of 128 dimensions. This vector space will be used to represent each unique image.
When training, first the generate creates an image, followed by training the discriminator, using the real images. Finally, the fake-generated image is used with the discriminator to determine the probability of being real.
Lastly, it will use the result from both the generator and discriminator to determine the loss value and in succession perform back-propagation.
The source code for the trained model can be found on GitHub as a python notebook.
First Train Model Around 2020
The first trained model was derived from some kind of GAN example. It was adjusted with some modifications to use both different datasets, and additionally, support 3 color channels. It yielded some kind of result. However, even after a 1000 epoch on a dataset of over 10K elements. The result was still not great. But had some kind of quality of an anime-looking face.
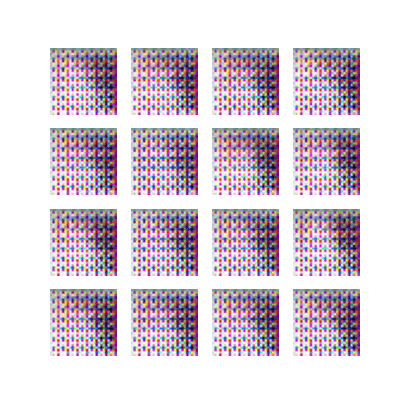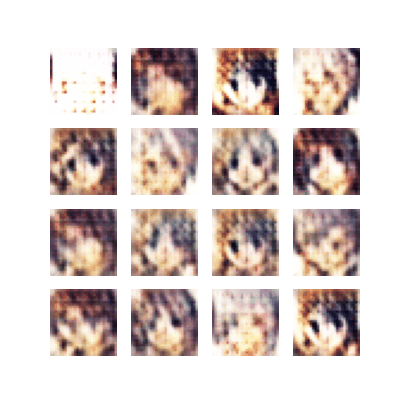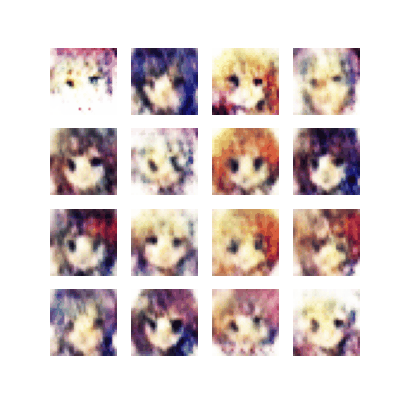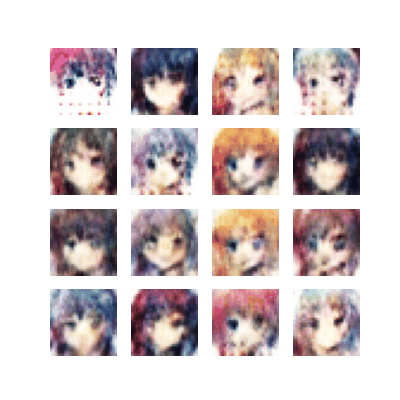










Improved Trained Model 2022

The improved model took many trials and errors in order to both understand and adjust both the models and the loss function.
The dataset GochiUsa_Faces was used. However, when examining the dataset, there exist many files that are both too small and lack anime face details. Instead, only faces with proper facial features and details were selected. The feature detailed was of the quality that the model was expected to generate.
In addition to the cleanup of the dataset, the chosen images were also upscale, using waifu2x. How much of a difference does it yield in the final trained model, probably not much. However, if training for higher resolution on a later date, then it will definitely.
After having to preprocess all the data, it ended up with around 26K images.

For future research, an attempt to create both a better dataset as well as use an alternative GAN technique in order to compare how much of an improvement it yields.
For even more details about GAN, it is recommended to read some of the popular papers about GAN. Since there exists many more than just the deep convolution generative adversarial network model.



Support me by donation or by using the Affiliate links for your next purchase to help maintain this website.


Free/Open software developer, Linux user, Graphic C/C++ software developer, network & hardware enthusiast.