

Snake – A classical game that has probably been programmed to every possible device, alongside the famous FPS game Doom. The game is about a snake eating all the apples and trying to survive as its body grows in length. Eating yourself or colliding with the wall result in a game over.
The game itself is extremely very easy to program from scratch. However, the bigger challenge is to create an AI that can complete the game or at least mimic human skills.
This problem may at first sound like a very easy problem and to some degree in the early game, it is very easy to reasonable results. However, as the snake grows in length, as it coils itself up, or get into a state where it must make a good decision to uncoil itself, making it no longer a simple problem. This is quite contradicting, based on how easy it is to implement the game itself.


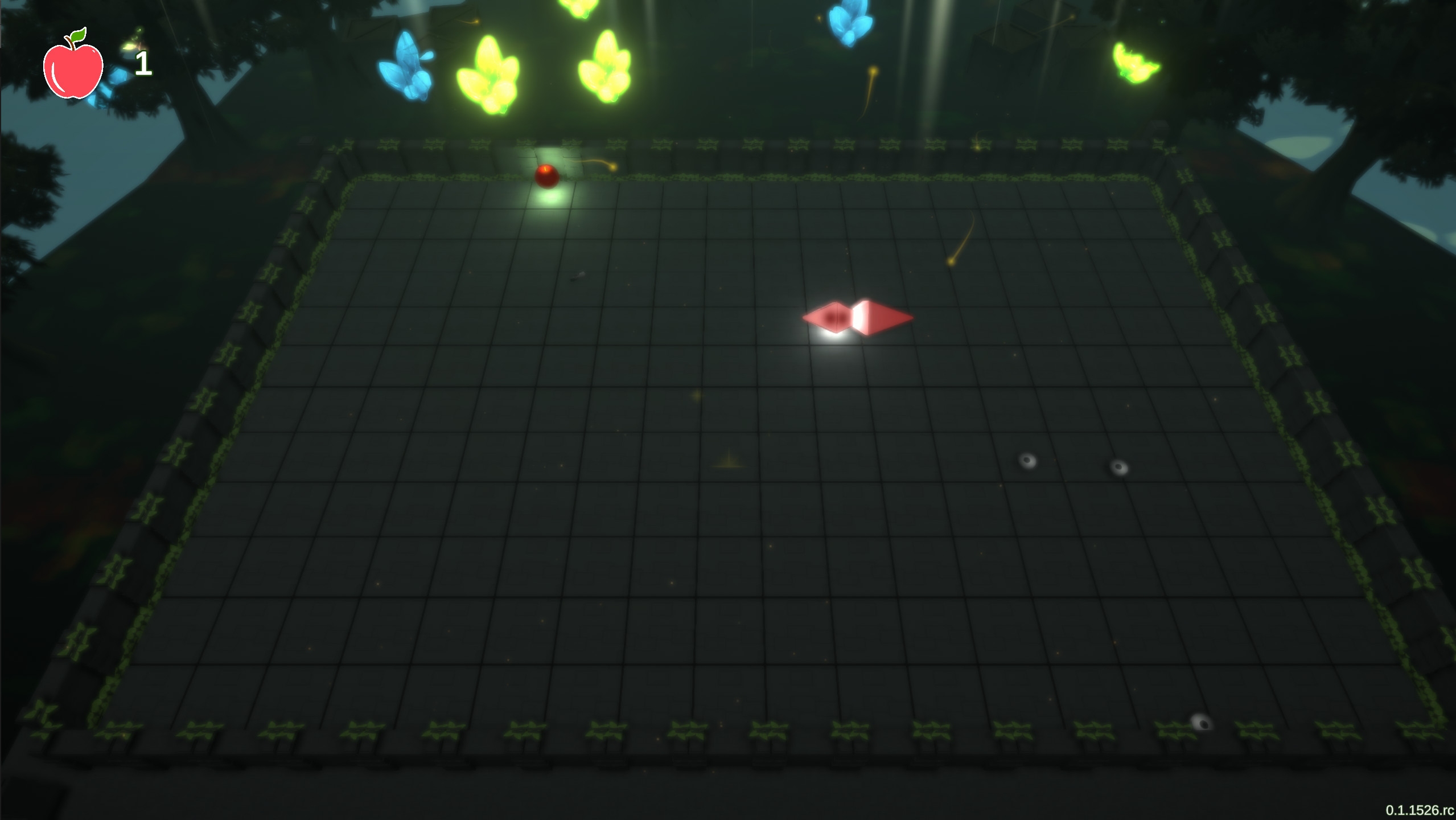

A snake game was developed with the Unity 3D engine in order to both create a fun standalone snake game, as well for research purposes. Although, the project took a bit longer than anticipated, but become a great educational purpose.
Possible Artificial intelligence
The following list is the various path algorithm used in the game to demonstrate each of their performance to solve the game.
- Hamilton – Visit whole path, part of discrete math/ graph theory
- A Star – Calculates the shorted path, part of graph theory
- Reinforcement Learning – Q Learning
- Reinforcement Learning -Q Deep Learning
Hamilton Path
The first is the Hamilton Path algorithm, it is the most simple algorithm of them all and possibly the least exciting, all the while yielding the best performance. This algorithm is based on the mathematical Hamilton problem in discrete/graph mathematics.
The simple idea is how to visit all the vertices in a graph while only visiting an individual vertex only once.
This yields that the snake will cycle over the same path. Creating a very non-interesting way of solve the game. Since it is not the most efficient and the least human like. Very cold and calculated. But solves the problem
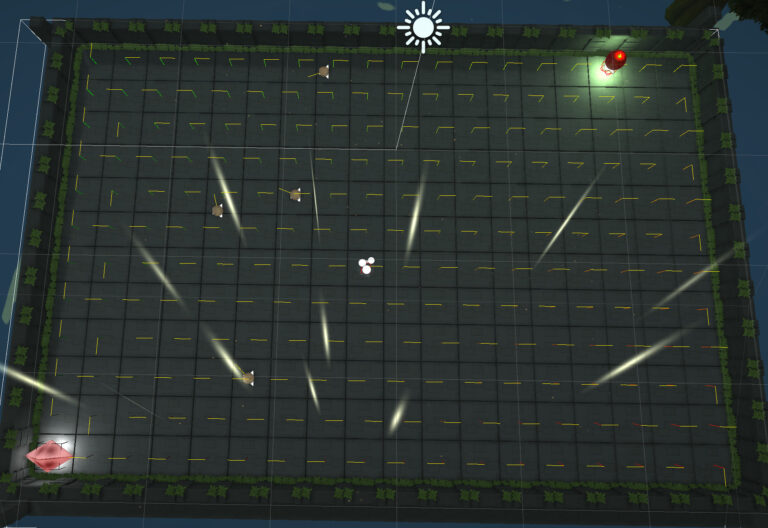
Reduce Hamilton Path
One approach to make the Hamilton Path a bit less cold and boring, is to reduce the path ahead. This is done by looking at all possible move the snake can do at the current point, check all the next vertices it can move to, and travel back to the snake head position. If it does not collide into the snake, and is the longest path it can reduce.
Shorted Path – Graph Theory – A Star
The following algorithms are based on finding the shortest path between two vertices. This is a common algorithm used in everyday life of finding the shortest driving path and etc.
Dijkstra is the simplest implementation and
A Star algorithm is an extension of the Dijkstra, in that it uses a heuristic approach, by using a measurement of distance.
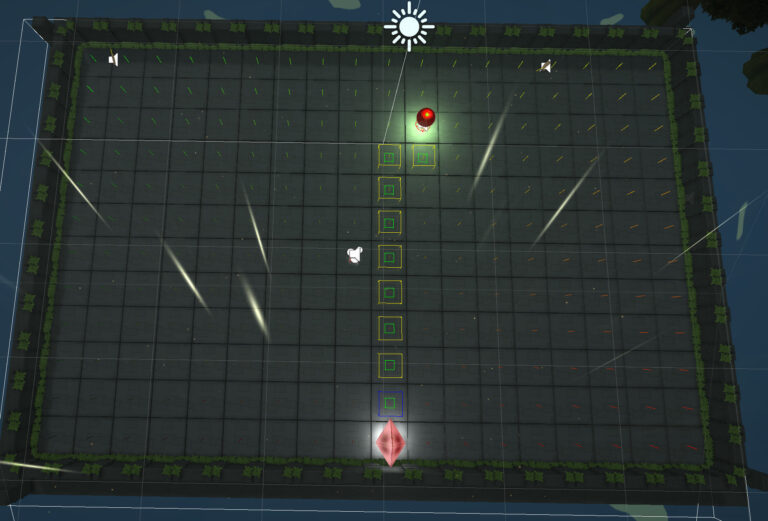
The A Star algorithm had to modified in order to work with the restriction of the snake movements. Because, the snake can only go left, right and forward. Whereas the A star algorithm would think that going backward was a valid path. This added additional restriction, and if no solution was found, a random direction was selected.
Late Game Challenge
During the early game of Snake, the A Star algorithm will do rather well, as much algorithm will. However, as the game progress and the snake body increases, the probability of coiling up increases. Thus A star algorithm in this case becomes a greedy algorithm, since it takes the best local shortest path However, it does not take into account the sequential apple positions and snake body. That is to say, it does not look a head in the future to compute what is the best path.
Q Learning – Reinforcement Learning
Finally, some modern dedicated AI/Machine Learning techniques. In contrast to the previous algorithms, this algorithm is based on that a small number of states and actions are presented and rewarded according to the actions take to win the game. By doing that, the snake finds a solution rather than hard-coding how it should do everything.
The first implementation is the simple one. Naive Q Learning – WIP
Q Deep Learning Policy
The next algorithm is also based on reinforcement learning but uses a Deep Learning neuron network in combination rather than Q Table. In this case, it is using the Unity ML Agent library. WIP


Support me by donation or by using the Affiliate links for your next purchase to help maintain this website.


Free/Open software developer, Linux user, Graphic C/C++ software developer, network & hardware enthusiast.