
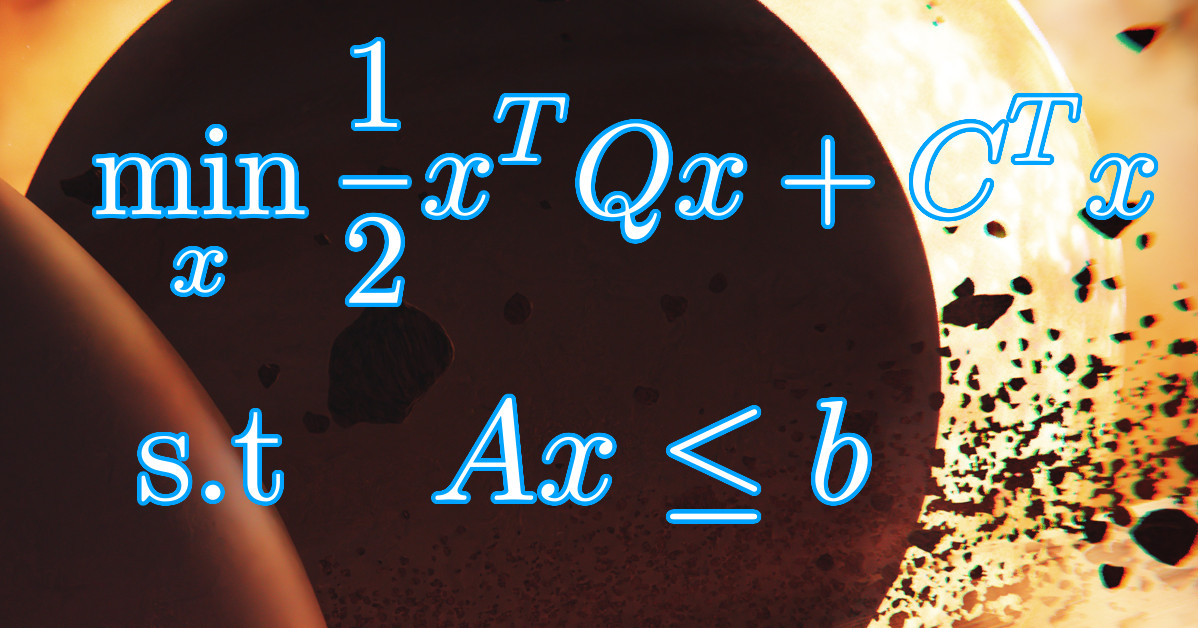
Quadratic Programming is a combination of multiple mathematical concepts. Quadratic approximation (Taylor Series), Constrained function as well cost/loss optimization. Combined, it creates a convex optimization problem. Meaning that the problem can only be solved if and only if the problem can be represented as a convex problem. Additionally, the solution can only be within the convex region of the problem.
Quadratic Programming is formulated as the following:
![\[\min_{x} \frac{1}{2}x^TQx + C^Tx\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-fff86655d1207f1f628b7c2570fd3d01_l3.png "Rendered by QuickLaTeX.com")
![\[\textrm{s.t} \quad Ax \le b\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-be7c4f432304bb9192e49e27e403440c_l3.png "Rendered by QuickLaTeX.com")
The formula states that, find the set of variables
 that will yield the smallest number (cost), while satisfying the constrained linear equation
that will yield the smallest number (cost), while satisfying the constrained linear equation  . Where
. Where  stands for subjected to.
stands for subjected to.When unfolding the linear algebraic expression we get the following sequence equation:
![\[\min_{x} a_0x^2_0+a_1x^2_1+...+a_nx^2_n+b_0x_0+b_1x_1+...+b_nx_n+c\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-732bc4367d225d476a80d6795a192874_l3.png "Rendered by QuickLaTeX.com")
The function with the min is the loss function that states how good the value is. It is used as for expressing what the optimization should attempt to optimize as well if the optimizer is going in the right direction.
Finally, the  is the quadratic approximation function that describes the optimization itself. Quadratic Programming is just a special case of using Quadratic Approximation and can be expressed as Polynomial Programming for generalizing.
is the quadratic approximation function that describes the optimization itself. Quadratic Programming is just a special case of using Quadratic Approximation and can be expressed as Polynomial Programming for generalizing.
Linear Programming
It should be notated that a subset of the quadratic programming cost optimization function is from linear programming. Thus it is suggested to learn it before quadratic programming. Since the cost function is a linear function (hyperplane) and simpler to comprehend/visualize.
![\[\min_{x} b_0x_0+b_1x_1+...+b_nx_n+c\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-bc1fbc55fe8e9124a730cfadb45b73df_l3.png "Rendered by QuickLaTeX.com")
![\[\textrm{s.t} \quad Ax \le d\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-d9c980b8c7eb3c5afdeb50956c4d07f5_l3.png "Rendered by QuickLaTeX.com")
Taylor Series – Approximation
The Quadratic approximation is derived from the Taylor Series, which is a definition of how a function can be re-expressed as the sum of an infinite sequence of derivative functions at a particular point. See the following definition:
![\[f(x)=\sum^{\infty}_{n=0}\dfrac{f^{(n)}(a)}{n!}(x-a)^n\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-1bf24c13ba7b9167b31858cc72b60536_l3.png "Rendered by QuickLaTeX.com")
For instance, a sine function,  , can be expressed as an infinite polynomial expression.
, can be expressed as an infinite polynomial expression.
However, it should be noted that working with infinite sequences is very much restricted when solving purely as a mathematical problem. Whereas applied mathematics in the real-world problem may not be able to make use of infinite sequence since it would require infinite computation.
Instead, since this is done in the real world and an infinite sequence is impossible, instead an approximate version can be opted for and computed. Where the amount of error will be proportional to what degree of the Taylor Series is used as well as the distance from the sampled point and the point that the approximate function is based on.
See the following Taylor Series definition:
![\[f(x)\thickapprox\sum^{K}_{n=0}\dfrac{f^{(n)}(a)}{n!}(x-a)^n\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-978495be0f6cc8b8481872f5ba3c7df9_l3.png "Rendered by QuickLaTeX.com")
Linear Approximation
For a linear approximation, it will essentially become the tangent line. Since it will have the shape of a linear function. Additionally, it can for any given dimension, which effectively makes it a hyperplane. Though a linear approximation is limited by that it is only good for the problems that have a linear relationship.
![\[f(x) = ax +c\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-f899067abf6169a74b3645963b6b20bc_l3.png "Rendered by QuickLaTeX.com")
Taylor Series
The Linear Approximation is derived from the Taylor Series, see the following.
![\[f(x) = \sum^{K=2}_{n=0}\dfrac{f^{(n)}(a)}{n!}(x-a)^n\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-cb5e8c71cd56256515b8f77cb18b4eee_l3.png "Rendered by QuickLaTeX.com")
![\[f(x) = c + ax = \frac{f^{(0)}(a)}{0!}(x - a)^0 + \frac{f^{(1)}(a)}{1!}(x - a)^1\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-6ac51e38392e77fc30966f5436afec68_l3.png "Rendered by QuickLaTeX.com")
The Taylor can be reduced into a condensed Algebraic equation, that is the same shape as the linear equation:
![\[L_f(x) = f(x_0) + \triangledown f(x_0)\cdot(x -x_0)\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-00a081509137436727ff692fd381bf40_l3.png "Rendered by QuickLaTeX.com")
Quadratic Approximation
The Quadratic approximation is the next level from the linear approximation one. It approximates the function around a certain point with a higher-level approximation.
It has the shape of a quadratic equation, see the following:
![\[f(x) = ax^2 + bx + c\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-9adf34e22ae9e229fe58aac573741c4c_l3.png "Rendered by QuickLaTeX.com")
Deriving the Quadratic Approximation from the Taylor series gives the following.
![\[f(x) = \sum^{K=3}_{n=0}\dfrac{f^{(n)}(a)}{n!}(x-a)^n\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-ddd447713d46a870ff71a31d0ea109dc_l3.png "Rendered by QuickLaTeX.com")
![\[f(x) = c + bx + ax^2 + = \frac{f^{(0)}(a)}{0!}(x - a)^0 + \frac{f^{(1)}(a)}{1!}(x - a)^1 + \frac{f^{(2)}(a)}{2!}(x - a)^2\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-a41aa006b0098ea7e5ca5a2f48cf22f0_l3.png "Rendered by QuickLaTeX.com")
![\[Q_f(x) = f(x_0) + \triangledown f(x_0)\cdot(x -x_0) + \frac{1}{2}(x-x_0)^TH_f(x_0)(x - x_0)\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-9bba4b1f6fce920860de28a50d1cec83_l3.png "Rendered by QuickLaTeX.com")
The expression
 First order Partial derivative in respect for all the variables of . It will have the shape of a vector.
First order Partial derivative in respect for all the variables of . It will have the shape of a vector.The expression
 is the Hessian Matrix, which contains all possible combinations of partial derivatives as a square matrix.
is the Hessian Matrix, which contains all possible combinations of partial derivatives as a square matrix.Partial Derivative
Partial Differential is rather straightforward to calculate. The first-order ordinary derivative is calculated for each of the variables individually. Resulting in a vector/list of derivatives, with the size (cardinality) equal to the number of variables.
For instance, given the following function with two variables.
![\[f(x,y) = x^2y + y^2x\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-5a8c3500a3ce9fa7fb69925c861dd95a_l3.png "Rendered by QuickLaTeX.com")
Thus computing the individual variable’s derivatives gives the following set of functions:
![\[\frac{\partial f}{\partial x} = 2xy + y^2\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-e73d72ed68892d18b24358c0b8f2c38a_l3.png "Rendered by QuickLaTeX.com")
![\[\frac{\partial f}{\partial y} = x^2 + 2yx\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-c84aa335ac4ecef39d7b3baa5382d4ed_l3.png "Rendered by QuickLaTeX.com")
Finally, it can be generalized as the following:
![\[\begin{bmatrix}\frac{\partial f}{\partial v_0}\\\frac{\partial f}{\partial v_1}\\\frac{\partial f}{\partial v_2}\\\cdots\\\frac{\partial f}{\partial v_{n-1}}\\\end{bmatrix} \le (\frac{\partial f}{\partial v_0},\frac{\partial f}{\partial v_1},\frac{\partial f}{\partial v_2},\cdots\frac{\partial f}{\partial v_{n-1}} )\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-ff7c64980c5cd4c2253801800b21f8e3_l3.png "Rendered by QuickLaTeX.com")
Side Note, the partial derivative is commonly used in optimization function. Like in gradient descent based optimization algorithm.
Hessian Matrix
Hessian Matrix is the second-order ordinary partial differential, expressed as a matrix that contains all the combinations of second-order partial differential. See the following for a two variables example function as a Hessian Matrix:
![\[\begin{bmatrix}\frac{\partial^2 f}{\partial x^2} & \frac{\partial^2 f}{\partial x \partial y}\\\frac{\partial^2 f}{\partial x \partial y} & \frac{\partial^2 f}{\partial y^2}\end{bmatrix}\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-60f92d4265b484a6ce571ba319a3383d_l3.png "Rendered by QuickLaTeX.com")
Since Hessian Matrix is a square matrix, when multiplied by the vector, it produces a vector.
Constraint
Constraints are additional conditions that a mathematical problem much satisfy. It is commonly expressed as subject to or s.t. See the following for an example:
![\[\min_{x,y} f(x,y) = x^2 + y^2\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-09d6f37f710df60c8cb7b9fd1112bc92_l3.png "Rendered by QuickLaTeX.com")
![\[\text{s.t } x = 1\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-11717068c7c4649ad0e3ead4e92f2a2d_l3.png "Rendered by QuickLaTeX.com")
The constraints can be expressed as either equality or inequality constraint. For simplicity, let us only consider linear constraints. See the following for the linear constraint expression:
![\[a_1x_1 + a_2x_2+\cdots+a_nx_n \le b\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-98ac6c1f55f97e449b9c95a049f2a83c_l3.png "Rendered by QuickLaTeX.com")
![\[Ax \le b\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-5e4701252fbc87b441e9c594c9b64e6a_l3.png "Rendered by QuickLaTeX.com")
When having a set of multiple constraints it can be expressed as a matrix equation. See the following statement. Where A is the constraint, V is the vector that is to be determined if in the
![\[\begin{bmatrix}A_{0} & A_{0,1} & \cdots & A_{0,n} \\A_{1,0} & A_{1,1} & \cdots & A_{1,n} \\\vdots & \vdots & \ddots & \vdots \\A_{n,0} & A_{1,1} & \cdots & A_{n,n}\end{bmatrix}\begin{bmatrix}V_0\\V_1\\\vdots\\V_n\end{bmatrix}\le\begin{bmatrix}B_0\\B_1\\\vdots\\B_n\end{bmatrix}\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-fbc35f70c9198a72dd4d9fda75979b56_l3.png "Rendered by QuickLaTeX.com")
All the constraints combined can creates a geometric shape. The combined constraints must yield a convex shape, which is one of the required properties for Quadratic Programming to work.

It can be though of that for every constraint, it is as if creating straight cut on a piece of paper. Eventually after many cuts, the final shape emerges.
Hyperplane
Given linear constraints, it can be interpret as a hyperplanes, which is a plan for any given vector space dimension. For 2D space, is a line, in 3D space is a plane and etc. That is to say a linear expression. This allows taking advantage of many properties of *Linear Algebra*. See the following expression of Hyperplane in linear-algebraic form.
![\[\hat{n}\cdot\vec{v}+d\le0\]](https://www.codeintrinsic.com/wp-content/ql-cache/quicklatex.com-dd01ba0a7f82d3d984eb9f93d519f962_l3.png "Rendered by QuickLaTeX.com")
Additionally, the hyperplane can be viewed as dividing the existing vector space into two sub-vector spaces. When computing a vector as a point with the hyperplane equation it will give a value. Where the sign determines on which side of the plane it is located.
Quadratic Programming Optimization Problem – Loss Function
Finally, the *loss function* is the function that will be the guiding expression on how well the optimization is going.
However, the question is what and how should it be expressed in our to guide the algorithm to optimize the problem in the way that is desired, alignment problem.
Optimization Stepping

Least Squares
The more simpler loss function is the MSE (Mean Square error), which computes the distance between values as the absolute value in order to determine how much error/loss.

Quadratic Programming in Programming
The QP programming as present above can not really be solved for any arbitrary problem with computer hardware. Rather it has to solve computational in order to find the best solution. It becomes related more to sequential quadratic programming (SQP). Where the idea is that similar to gradient descent a point within the convex vector space region walks in steps in till it finds the point with the lowest loss value. That is to say in till it finds the lowest valley. How it is implemented is a completely different problem. Fortunately, there exist many libraries in many various programming languages that have solved that problem. Thus, the problem becomes how to express our problem as a quadratic programming problem.
Quadratic Programming Challenge
The Challenge with Quadratic Programming is not really the math part. Rather it is how to configure the variables Q (Quadratic Cost) p (Linear Cost) and A (Constraint) in hope that it execute as it is intended.
Example Case of Quadratic Programming
Work In Progress
Quadratic Programming Resources
Quadratic Programming Software Library Example Using OSQP



Support me by donation or by using the Affiliate links for your next purchase to help maintain this website.


Free/Open software developer, Linux user, Graphic C/C++ software developer, network & hardware enthusiast.